Summary Digital Accessibility & Privacy Opacity Neglects
The OpenAI GPT-5 product page is inaccessible without JavaScript and cookies, obscuring meaningful human rights evaluation. Observable structural signals indicate accessibility barriers and opaque privacy practices. The vast majority of UDHR provisions cannot be assessed due to dynamic content loading requirements.
For day to day coding, I've found Anthropic to be killing it with Sonnet 3.7 and now Sonnet 4, and Claude Code feeling like it has even bigger advantages over when it's used in Cursor (And I can't explain why).
I don't even try to use the OpenAI models because it's felt like night and day.
Hopefully GPT-5 helps them catch up. Although I'm sure there are 100 people that have their own personal "hopefully GPT-5 fixes my personal issue with GPT4"
The marketing copy and the current livestream appear tautological: "it's better because it's better."
Not much explanation yet why GPT-5 warrants a major version bump. As usual, the model (and potentially OpenAI as a whole) will depend on output vibe checks.
Watching the livestream now, the improvement over their current models on the benchmarks is very small. I know they seemed to be trying to temper our expectations leading up to this, but this is much less improvement than I was expecting
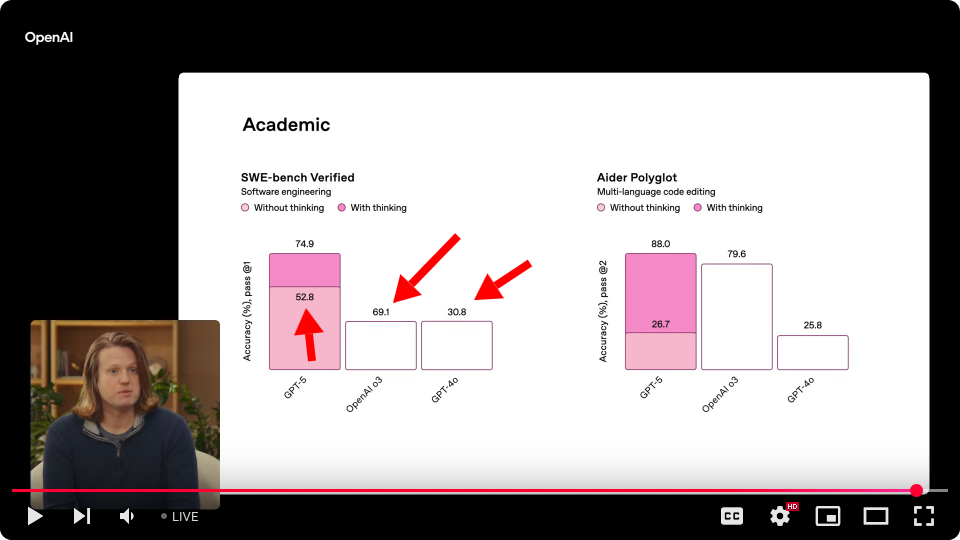
GPT-5 non-thinking is labeled 52.8% accuracy, but o3 is shown as a much shorter bar, yet it's labeled 69.1%. And 4o is an identical bar to o3, but it's labeled 30.8%...
Wait, isn't the Bernoulli effect thing they're demoing now wrong? I thought that was a "common misconception" and wings don't really work by the "longer path" that air takes over the top, and that it was more about angle of attack (which is why planes can fly upside down).
It seems like it's actually an ideal "trick" question for an LLM actually, since so much content has been written about it incorrectly. I thought at first they were going to demo this to show that it knew better, but it seems like it's just regurgitating the same misleading stuff. So, not a good look.
With 74.9% on SWE-bench, this inches out Claude Opus 4.1 at 74.5%, but at a much cheaper cost.
For context, Claude Opus 4.1 is $15 / 1M input tokens and $75 / 1M output tokens.
> "GPT-5 will scaffold the app, write files, install dependencies as needed, and show a live preview. This is the go-to solution for developers who want to bootstrap apps or add features quickly." [0]
Since Claude Code launched, OpenAI has been behind. Maybe the RL on tool calling is good enough to be competitive now?
> For an airplane wing (airfoil), the top surface is curved and the bottom is flatter. When the wing moves forward:
> * Air over the top has to travel farther in the same amount of time -> it moves faster -> pressure on the top decreases.
> * Air underneath moves slower -> pressure underneath is higher
> * The presure difference creates an upward force - lift
Isn't that explanation of why wings work completely wrong? There's nothing that forces the air to cover the top distance in the same time that it covers the bottom distance, and in fact it doesn't. https://www.cam.ac.uk/research/news/how-wings-really-work
Very strange to use a mistake as your first demo, especially while talking about how it's phd level.
> . . . with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say “think hard about this” in the prompt).
So that's not really a unified system then, it's just supposed to appear as if it is.
This looks like they're not training the single big model but instead have gone off to develop special sub models and attempt to gloss over them with yet another model. That's what you resort to only when doing the end-to-end training has become too expensive for you.
If this performs well in independent needle-in-haystack and adherence evaluations, this pricing with this context window alone would make GPT-5 extremely competitive with Gemini 2.5 Pro and Claude Opus 4.1, even if the output isn't a significant improvement over o3. If the output quality ends up on-par or better than the two major competitors, that'd be truly a massive leap forward for OpenAI, mini and nano maybe even more so.
Some people have hypothesized that GPT-5 is actually about cost reduction and internal optimization for OpenAI, since there doesn't seem to be much of a leap forward, but another element that they seem to have focused on that'll probably make a huge difference to "normal" (non-tech) users is making precise and specifically worded prompts less necessary.
They've mentioned improvements in that aspects a few times now, and if it actually materializes, that would be a big leap forward for most users even if underneath GPT-4 was also technically able to do the same things if prompted just the right way.
It is frequently suggested that once one of the AI companies reaches an AGI threshold, they will take off ahead of the rest. It's interesting to note that at least so far, the trend has been the opposite: as time goes on and the models get better, the performance of the different company's gets clustered closer together. Right now GPT-5, Claude Opus, Grok 4, Gemini 2.5 Pro all seem quite good across the board (ie they can all basically solve moderately challenging math and coding problems).
As a user, it feels like the race has never been as close as it is now. Perhaps dumb to extrapolate, but it makes me lean more skeptical about the hard take-off / winner-take-all mental model that has been pushed.
Would be curious to hear the take of a researcher at one of these firms - do you expect the AI offerings across competitors to become more competitive and clustered over the next few years, or less so?
That SWE-bench chart with the mismatched bars (52.8% somehow appearing larger than 69.1%) was emblematic of the entire presentation - rushed and underwhelming. It's the kind of error that would get flagged in any internal review, yet here it is in a billion-dollar product launch. Combined with the Bernoulli effect demo confidently explaining how airplane wings work incorrectly (the equal transit time fallacy that NASA explicitly debunks), it doesn't inspire confidence in either the model's capabilities or OpenAI's quality control.
The actual benchmark improvements are marginal at best - we're talking single-digit percentage gains over o3 on most metrics, which hardly justifies a major version bump. What we're seeing looks more like the plateau of an S-curve than a breakthrough. The pricing is competitive ($1.25/1M input tokens vs Claude's $15), but that's about optimization and economics, not the fundamental leap forward that "GPT-5" implies. Even their "unified system" turns out to be multiple models with a router, essentially admitting that the end-to-end training approach has hit diminishing returns.
The irony is that while OpenAI maintains their secretive culture (remember when they claimed o1 used tree search instead of RL?), their competitors are catching up or surpassing them. Claude has been consistently better for coding tasks, Gemini 2.5 Pro has more recent training data, and everyone seems to be converging on similar performance levels. This launch feels less like a victory lap and more like OpenAI trying to maintain relevance while the rest of the field has caught up. Looking forward to seeing what Gemini 3.0 brings to the table.
I'm not really convinced, the benchmark blunder was really strange but the demos were quite underwhelming, and it appears this was reflected by a huge market correction in the betting markets as to who will have the best AI by end of the year.
What excites me now is that Gemini 3.0 or some answer from Google is coming soon and that will be the one I will actually end up using. It seems like the last mover in the LLM race is more advantageous.
I am thoroughly unimpressed by GPT-5. It still can't compose iambic trimeters in ancient Greek with a proper penthemimeral cæsura, and it insists on providing totally incorrect scansion of the flawed lines it does compose. I corrected its metrical sins twice, which sent it into "thinking" mode until it finally returned a "Reasoning failed" error.
There is no intelligence here: it's still just giving plausible output. That's why it can't metrically scan its own lines or put a cæsura in the right place.
Ok this[0] sounds very, uh bold to me? Surely this is going to break a ton of workflows etc seemingly with nearly no notice? I'm assuming 'launches' equates with 'fully rolls out' or something but it's not that clear to me.
When GPT-5 launches, several older models will be retired, including:
- GPT-4o
- GPT-4.1
- GPT-4.5
- GPT-4.1-mini
- o4-mini
- o4-mini-high
- o3
- o3-pro
If you open a conversation that used one of these models, ChatGPT will automatically switch it to the closest GPT-5 equivalent. Chats with 4o, 4.1, 4.5, 4.1-mini, o4-mini, or o4-mini-high will open in GPT-5, chats with o3 will open in GPT-5-Thinking, and chats with o3-Pro will open in GPT-5-Pro (available only on Pro and Team).
They really nerfed Plus[0]. 80 messages every 3 hours for normal GPT-5. And only 200 messages per week for GPT-5 Thinking. It seems like terrible value.
Before it was:
100 o3 per week
100 o4-mini-high per day
300 o4-mini per day
50 4.5 per week
Colleagues were saying that horizon alpha and beta were looking better than claude4 for frontend stuff, especially newer frameworks. I think the idea of having full + mini + nano is really good, as long as the smaller ones can reasonably handle small-ish tasks. You'd have your architect / plan whatever sessions with the large one, scoping out regular tasks for the -mini version and then the really easy ones to -nano.
4.1 was almost usable in that fashion. I had 4.1-nano working in cline with really trivial stuff (add logging, take this example and adapt it in this file, etc) and it worked pretty well most of the time.
Whatever the benchmarks might say, there's something about Claude that seems to deliver consistently (although not always perfect) quite reliable outputs across various coding tasks. I wonder what that 'secret sauce' might be and whether GPT-5 has figured it out too.
Well, since (like you pointed out) using the Anthropic models in different settings is not that exciting anymore, the difference is what Claude Code does. It's a good product.
That said, I recall reading somewhere that it's a combination of effects, and the Bernoulli effect contributes, among many others. Never heard an explanation that left me completely satisfied, though. The one about deflecting air down was the one that always made sense to me even as a kid, but I can't believe that would be the only explanation - there has to be a good reason that gave rise to the Bernoulli effect as the popular explanation.
And you can tell that effect makes some sense of you hold a sheet of paper and blow air over it - it will rise. So any difference in air speed has to contribute.
Yeah, they sure clicked away from it very fast and kept adjusting the scrollbars. It was confusing what it was trying to display. Furthermore, the prompt contained "Canvas" and "SVG" while as someone with webdev experience these are certainly familiar concepts, i wouldn't consider those in the "casual lexicon" for a random user trying to help a middle schooler with homework. I'm not impressed...
IMO Claude 3.7 could have done a similar / better job with that a year ago.
As someone who spent years quadruple checking every figure in every slide for years to avoid a mistake like this, it’s very confusing to see this out of the big launch announcement of one of the most high profile startups around.
Even the small presentations we gave to execs or the board were checked for errors so many times that nothing could possibly slip through.
It makes it look like the presentation is rushed or made last minute. Really bad to see this as the first plot in the whole presentation. Also, I would have loved to see comparisons with Opus 4.1.
Edit: Opus 4.1 scores 74.5% (https://www.anthropic.com/news/claude-opus-4-1). This makes it sound like Anthropic released the upgrade to still be the leader on this important benchmark.
And they included Flex pricing, which is 50% cheaper if you're willing to wait for the reply during periods of high load. But great pricing for agentic use with that cached token pricing, Flex or not.
Unless someone figures how to make these models a million(?) times more efficient or feed them a million times more energy I don’t see how AGI would even be a twinkle in the eye of the LLM strategies we have now.
Yeah, the explanation is just shallow enough to seem correct and deceive someone who doesn't grasp really well the subject.
No clue how they let it pass, that without mentioning the subpar diagram it created, really didn't seem like something miles better than what previous models can do already.
I switched immediately because of pricing, input token heavy load, but it doesn't even work. For some reason they completely broke the already amateurish API.
As someone who tries to push the limits of hard coding tasks (mainly refactoring old codebases) to LLMs with not much improvement since the last round of models, I'm finding that we are hitting the reduction of rate of improvement on the S-curve of quality. Obviously getting the same quality cheaper would be huge, but the quality of the output day to day isn't noticeable to me.
It's an extremely famous example of a widespread misconception. I don't know anything about aeronautical engineering but I'm quite familiar with the "equal transit time fallacy."
I have a suspicion that while the major AI companies have been pretty samey and competing in the same space for a while now, the market is going to force them to differentiate a bit, and we're going to see OpenAI begin to lose the race toward extremely high levels of intelligence instead choosing to focus on justifying their valuations by optimizing cost and for conversational/normal intelligence/personal assistant use-cases. After all, most of their users just want to use it to cheat at school, get relationship advice, and write business emails. They also have Ive's company to continue investing in.
Meanwhile, Anthropic & Google have more room in their P/S ratios to continue to spend effort on logarithmic intelligence gains.
Doesn't mean we won't see more and more intelligent models out of OpenAI, especially in the o-series, but at some point you have to make payroll and reality hits.
Also, the code demos are all using GPT-5 MAX on Cursor. Most of us will not be able to use it like that all the time. They should have showed it without MAX mode as well
Companies are collections of people, and these companies keep losing key developers to the others, I think this is why the clusters happen. OpenAI is now resorting to giving million dollar bonuses to every employee just to try to keep them long term.
Editorial Channel
What the content says
ND
PreamblePreamble
No content accessible
ND
Article 1Freedom, Equality, Brotherhood
No content accessible
ND
Article 2Non-Discrimination
No content accessible
ND
Article 3Life, Liberty, Security
No content accessible
ND
Article 4No Slavery
No content accessible
ND
Article 5No Torture
No content accessible
ND
Article 6Legal Personhood
No content accessible
ND
Article 7Equality Before Law
No content accessible
ND
Article 8Right to Remedy
No content accessible
ND
Article 9No Arbitrary Detention
No content accessible
ND
Article 10Fair Hearing
No content accessible
ND
Article 11Presumption of Innocence
No content accessible
ND
Article 12Privacy
Medium Practice
No editorial content on privacy visible
Observable Facts
Page displays message 'Enable JavaScript and cookies to continue'
Inferences
Requiring cookies without visible privacy disclosure in accessible content suggests potential lack of transparency in data handling practices
ND
Article 13Freedom of Movement
No content accessible
ND
Article 14Asylum
No content accessible
ND
Article 15Nationality
No content accessible
ND
Article 16Marriage & Family
No content accessible
ND
Article 17Property
No content accessible
ND
Article 18Freedom of Thought
No content accessible
ND
Article 19Freedom of Expression
No content accessible
ND
Article 20Assembly & Association
No content accessible
ND
Article 21Political Participation
No content accessible
ND
Article 22Social Security
No content accessible
ND
Article 23Work & Equal Pay
No content accessible
ND
Article 24Rest & Leisure
No content accessible
ND
Article 25Standard of Living
No content accessible
ND
Article 26Education
Medium Practice
No educational content observable
Observable Facts
Page displays 'Enable JavaScript and cookies to continue' with no fallback content
Inferences
Mandatory JavaScript requirement excludes users with disabilities or technology limitations, violating equal access to information principles
ND
Article 27Cultural Participation
No content accessible
ND
Article 28Social & International Order
No content accessible
ND
Article 29Duties to Community
No content accessible
ND
Article 30No Destruction of Rights
No content accessible
Structural Channel
What the site does
-0.25
Article 12Privacy
Medium Practice
Structural
-0.25
Context Modifier
ND
SETL
ND
Page requires cookies to proceed; privacy policy and cookie disclosure not visible in accessible portion, creating opacity around data collection practices
-0.30
Article 26Education
Medium Practice
Structural
-0.30
Context Modifier
ND
SETL
ND
Page requires JavaScript to display content; creates accessibility barrier preventing equal access to information for users without JavaScript support or using assistive technologies
Parse failure for model nemotron-nano-30b: Error: Failed to parse OpenRouter JSON: SyntaxError: Expected ',' or '}' after property value in JSON at position 10866 (line 445 column 4). Extracted text starts with: {
"schema_version": "3.7",
--
2026-02-26 08:30
dlq
Dead-lettered after 1 attempts: GPT-5
--
2026-02-26 08:30
eval_retry
OpenRouter API error 400 model=step-3.5-flash
--
2026-02-26 08:30
eval_failure
Evaluation failed: Error: OpenRouter API error 400: {"error":{"message":"Provider returned error","code":400,"metadata":{"raw":"{\"error\":{\"message\":\"response_format json_object is not supported for this model\",\"t
{kind=link}